El 56% de las bases de datos de las grandes empresas de Colombia tienen mala calidad según el informe interno de Deyde DataCentric. Debido a la digitalización y al gran volumen de captura de registros de datos de estos últimos dos años, y teniendo en cuenta que el ciclo de vida de los datos en las empresas se limita a tres meses antes de que pierdan su calidad, los equipos de datos se enfrentan a ficheros con muchos problemas de calidad.
La dificultad más común que se produce es la falta de visión única del cliente. Es decir, los empresarios se encuentran con registros duplicados de una misma persona. Esto se produce por tener varias fuentes de entrada de datos, por ejemplo, el sitio web, formularios de landings, publicidad en redes sociales… La mayoría de estos registros están llenos de discrepancias e incoherencias hasta que consigue relacionar y cribar la información correcta con la persona correcta.
Otra problemática está relacionada con las direcciones de correo electrónico. Muchos emails que se introducen en formularios contienen errores o no existen. Es muy común que al escribir las direcciones se comentan errores de escritura, entren caracteres no permitidos o estén mal formateadas (ausencia de arrobas, espacios, etcétera).
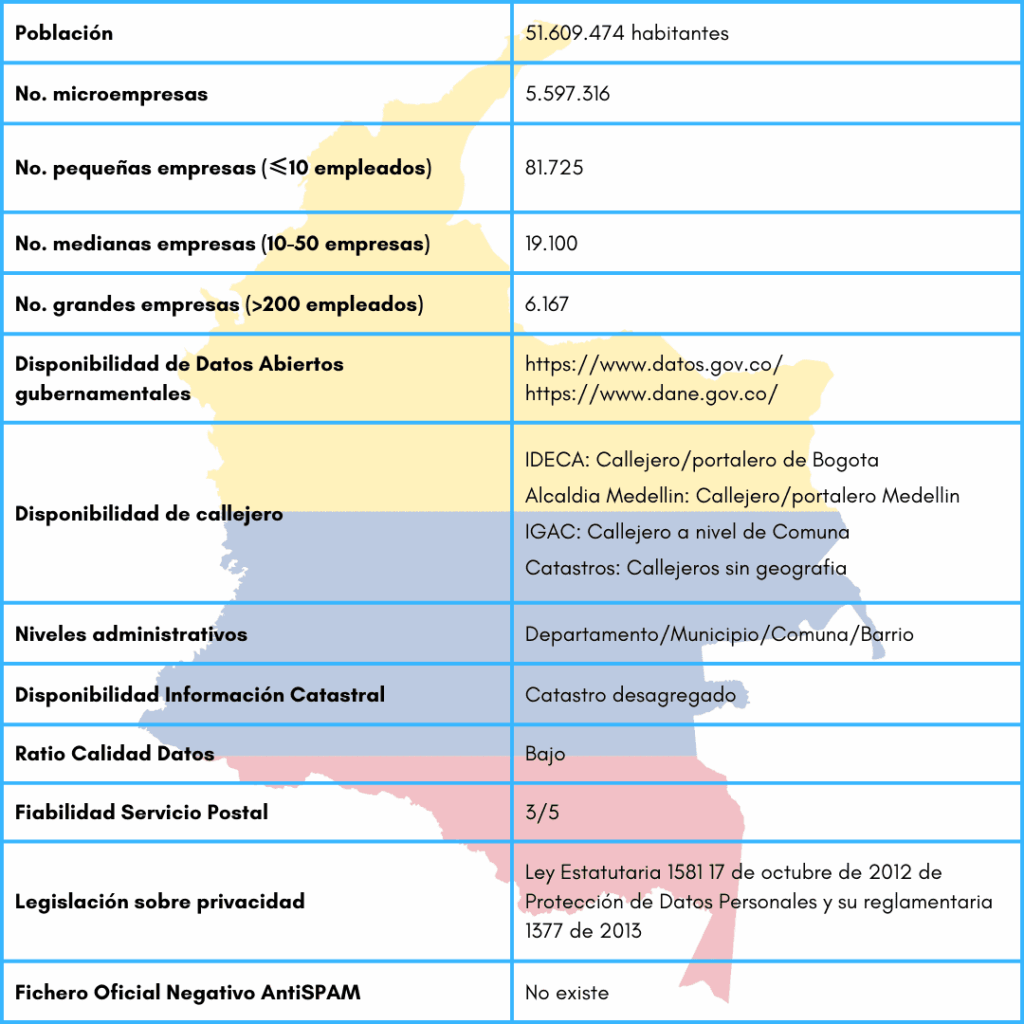
Por último, debemos hablar de las direcciones postales. La nomenclatura urbana en Colombia se basa en un modelo numérico. A nivel administrativo, existen callejeros y catastros, pero utilizan diversas fuentes de datos. Además, no fue hasta 2013 que se empezó a utilizar el código postal como iniciativa para facilitar y automatizar el encaminamiento de los envíos postales. Todo esto contribuye a una baja calidad de datos postales.
A estas alturas en la transformación digital del país, las empresas colombianas no se pueden conformar con solo capturar información. Como tal, se centran en prácticas innovadoras de automatización de procesos mediante, por ejemplo, la gestión de inteligencia artificial.
Sin duda, existe un gran interés entre las empresas colombianas en convertirse en organizaciones guiadas por datos y sacar el mayor provecho de los mismos. Pero el camino para llegar a ello no es sencillo. ¿Qué dificulta la implementación de la calidad de datos en Colombia? Los motivos los analizamos en este e-book gratuito, junto a varios casos de éxito de empresas colombianas que han dejado sus datos en manos de Deyde DataCentric.